FLUX.1 Kontext: A Context-Aware Multimodal Image Generation and Editing Engine from Black Forest Labs
In the evolving landscape of multimodal AI, Black Forest Labs has introduced a powerful new model: FLUX.1 Kontext — a next-generation engine for context-aware image generation and editing. Unlike traditional text-to-image systems like DALL·E or Stable Diffusion, Kontext can simultaneously understand both text and image inputs, enabling dynamic and iterative visual editing that’s more intuitive and consistent than ever before.
🚧 Limitations of Traditional Text-to-Image Models
While tools like DALL·E and Stable Diffusion have democratized AI-generated imagery, they still come with significant constraints:
- Lack of image input as a context modifier.
- Poor character continuity across scenes.
- Inefficient or complex local editing workflows.
- Noticeable image degradation after multiple edits.
- Slow inference speed, making real-time interaction impractical.
🎯 The Mission of FLUX.1 Kontext
FLUX.1 Kontext aims to build a true context-aware visual engine — where users can direct image generation with a blend of text prompts and image inputs, allowing intuitive control with consistency in character, style, and structure.
Think of it as the seamless fusion of Photoshop*’s flexibility and *GPT's contextual understanding — all in a single, efficient AI system.

🌟 Key Highlights of FLUX.1 Kontext
🧍 Character & Style Consistency
Maintain the same character appearance, pose, and expression across multiple scenes. Whether creating a comic, brand avatar, or storyboard, Kontext preserves identity and visual language.
Use Case: Build a coherent narrative or visual series without manually retouching every frame.
🎯 Localized Editing Without Hassle
Edit specific regions of an image without disturbing the rest. No need for masks, segmentation, or layers — just describe the change.
For example: “Change the dress color to red” — Kontext does it precisely, leaving everything else untouched.
🧠 Text + Image Prompting
Combine natural language and image uploads to direct generation. Whether modifying an uploaded photo or enhancing a draft, FLUX.1 understands both modes natively.
Ideal for iterative workflows: upload an image → describe desired changes → repeat as needed.
🔁 Multi-Step Iterative Editing
One of the model’s most groundbreaking features is its multi-round editing ability. You can apply sequential changes that build upon each other:
“Make her smile” → “Add sunglasses” → “Change the background to a cityscape” → “Put a logo on her shirt”
This chained reasoning is unprecedented in visual AI editing tools.
⚡ Ultra-Fast Inference
With up to 8x faster processing than traditional models, FLUX.1 enables real-time interactivity. Whether you're testing ideas or showcasing results to stakeholders, latency is no longer a barrier.
🧪 KontextBench: A New Benchmark for Context-Aware Image Models
To validate the performance of FLUX.1, Black Forest Labs introduced KontextBench, a benchmark suite measuring six critical dimensions:
- Accuracy of text-guided edits
- Image fidelity and visual consistency
- Character identity stability across frames
- Layout and text-image alignment
- Stability in multi-round editing
- Overall inference efficiency
🥇 Top Performer
According to initial results, FLUX.1 Kontext [pro] is among the best-performing models on:
- Character consistency
- Text prompt precision

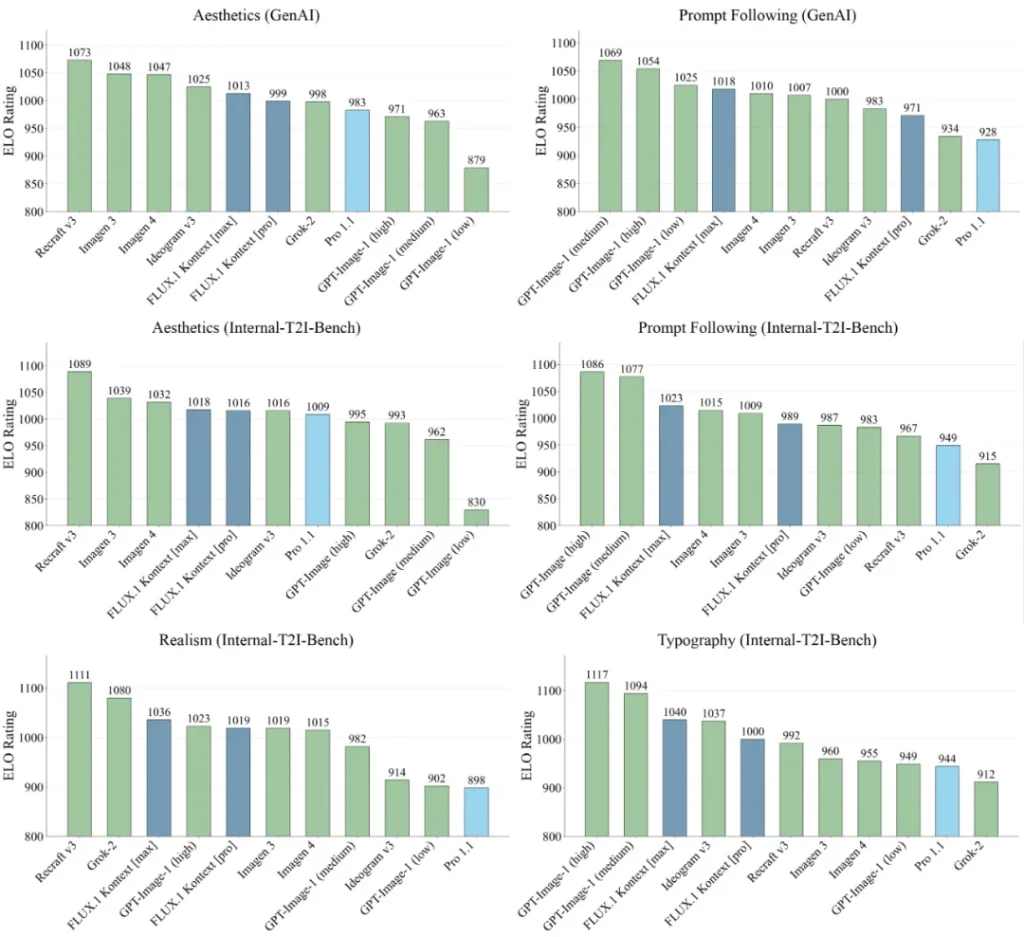
These capabilities make it a standout choice for creators, designers, and developers seeking reliable control over image generation workflows.
🔧 Model Variants and Use Cases
| Variant | Description |
|---|---|
| Kontext [pro] | Best for fast, consistent iteration across character-driven scenes. |
| Kontext [max] | High-fidelity version with enhanced prompt following, layout performance, and image stability. |
| Kontext [dev] | Open-weight version for research and experimentation — currently in private beta. |
🖥 FLUX Playground: Hands-On, No-Code Editing Interface
To make the model accessible, BFL also launched the FLUX Playground, a no-code interactive tool for:
- Uploading images and testing text-driven edits.
- Exploring multi-round changes with visual step tracking.
- Rapid prototyping and client demonstrations.
This tool is ideal for both creators and AI developers who want to integrate or explore the model's capabilities without setting up infrastructure.
⚠️ Current Limitations to Keep in Mind
While FLUX.1 Kontext is impressive, it’s still under active development. Black Forest Labs has acknowledged several caveats:
- Quality degradation after too many edit rounds.
- Occasional misinterpretation of complex prompts.
- Weakness in commonsense or structural reasoning.
- Potential loss of fine details during model compression.
These trade-offs suggest the model is best suited for concept design, prototyping, storytelling, and scene creation — rather than high-end final rendering tasks.
🤝 Platform Availability
FLUX.1 Kontext [pro] and [max] are already live via several partner platforms, including:
- Creation Tools: Krea.ai, Freepik, Lightricks, OpenArt, Leonardo AI
- Infra Partners: FAL, Replicate, RunwareAI, DataCrunch.io, TogetherCompute
Looking for more multimodal tools? Check out our Image Generation and Design & UI sections on AI-Kit.
FLUX.1 Kontext signals a meaningful shift toward true multimodal interaction in creative workflows. By combining textual reasoning, visual context, and high-speed iteration, it offers a glimpse of the next frontier in AI-powered design.
Whether you're prototyping a character, designing interactive visuals, or experimenting with visual storytelling — Kontext offers a flexible, contextually-aware solution worth exploring.
Explore more cutting-edge AI tools and creative engines on AI-Kit.site — your curated hub for next-gen productivity and innovation.